
Key Takeaway
- Agentic Vision enables AI to actively “investigate” images using code execution, rather than just passively viewing them.
- Spatial reasoning allows the model to understand depth, stacking orders, and empty spaces without manual training.
- The “Think, Act, Observe” loop simulates human problem-solving, creating verifiable data trails for industrial compliance.
- Zero-shot automation means robots can handle novel items (like a specific mug or engine part) without new programming.
- Code-driven annotation reduces hallucinations by forcing the AI to draw bounding boxes and verify pixel coordinates.
Table of Contents
ToggleCan AI Organize a Kitchen Cabinet?
The latest demonstration of Agentic Vision in Gemini 3 Flash answers a question that has plagued robotics for decades: Can a machine understand “clutter”?
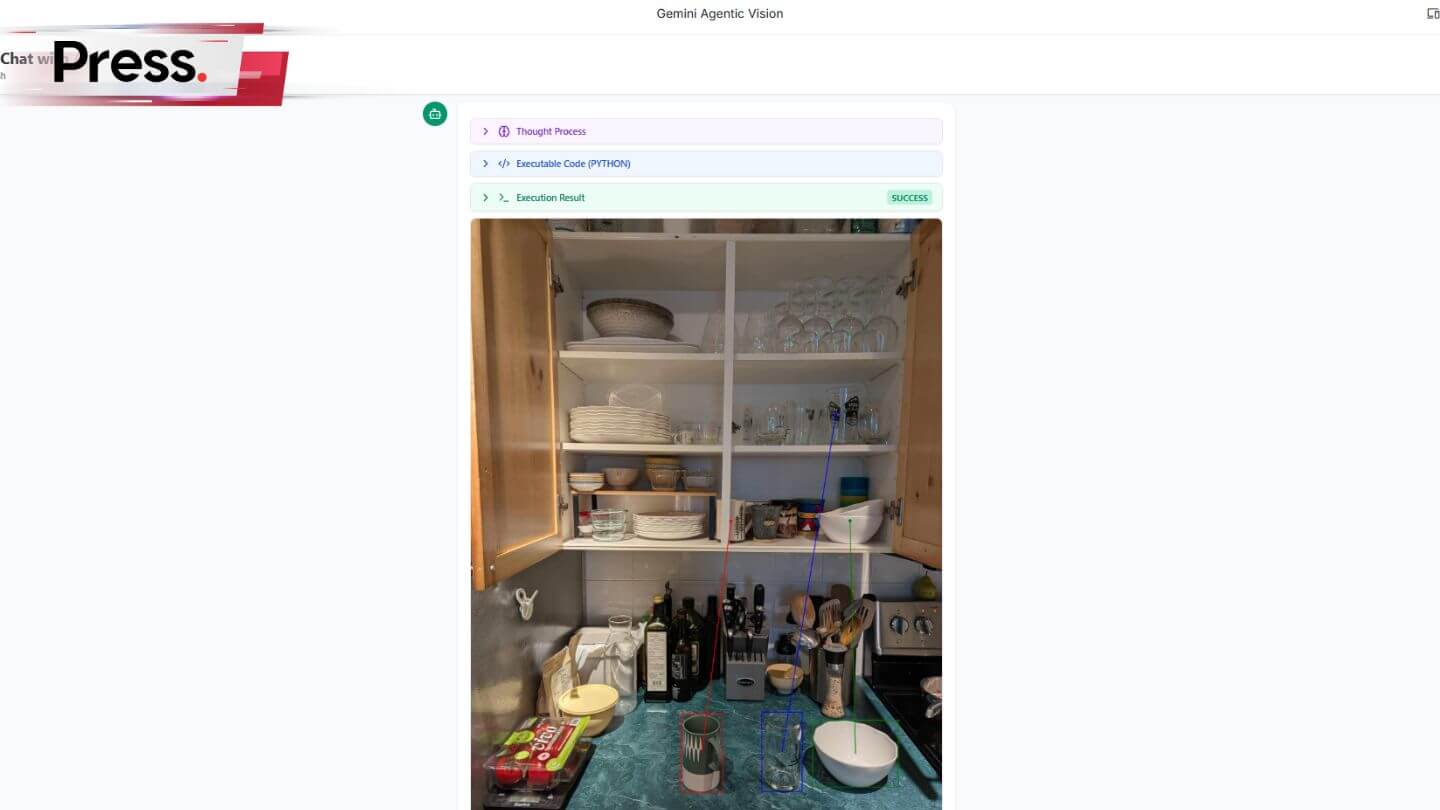
In a recent demo, users showed Gemini a photo of an empty kitchen cabinet and a countertop full of random dishes.
The AI didn’t just list the items; it drew precise vectors connecting each mug, bowl, and glass to its logical storage spot based on size, stacking ability, and usage patterns.
While organizing a kitchen is convenient, the implications for industrial automation are profound.
If an AI can autonomously figure out where a specific “green patterned mug” belongs on a shelf, it can figure out where a specific gear belongs in a transmission assembly, without a single line of custom code.

For tech firms and manufacturers, communicating this shift from “automated” to “autonomous” is critical. A specialized PR Agency Malaysia can help articulate how these agentic capabilities differ from standard machine vision, positioning forward-thinking companies as leaders in the next industrial revolution.
🧾 Comparison: Standard Vision vs. Agentic Vision
Feature | Standard Machine Vision | Agentic Vision (Gemini 3 Flash) |
Process | Passive “glance” at a static image. | Active “investigation” (Zoom, Inspect, Calculate). |
Handling Detail | Often misses small text or fine cracks. | Zooms in and executes code to verify details. |
Spatial Awareness | Requires hard-coded coordinates/training. | Understands “empty space” and “fit” intuitively. |
Output | Text description or simple classification. | Actionable code, coordinates, and physical plans. |
Best For | Fixed assembly lines (same object every time). | Dynamic environments (warehouses, homes). |
How Agentic Vision Works
Visual Reasoning Meets Code Execution
The core innovation in Gemini 3 Flash is the move from a static process to an agentic loop. Traditionally, a Vision-Language Model (VLM) looks at an image once and guesses. Agentic Vision employs a “Think, Act, Observe” loop:
- Think: The model analyzes the request (e.g., “Where does this part fit?”).
- Act: It writes and executes Python code to inspect the image—perhaps counting pixels to measure a gap or drawing a bounding box to confirm an object’s edge.
- Observe: It reviews the output of its code to verify its assumption before making a final decision.
This “visual scratchpad” approach significantly reduces errors in high-stakes environments like manufacturing or logistics.
From Kitchen Counter to Assembly Line
The principles used to organize a home kitchen map directly to industrial challenges.
✅ The Kitchen Demo (Spatial Logic)
The Scenario:
A user presents a disorganized set of dishes and open shelving.
The Agentic Process:
- Identification: The AI segments individual items (bowls vs. plates) despite them being stacked or partially obscured.
- Space Analysis: It calculates the vertical clearance of the shelves.
- Logic Application: It determines that heavy stacks of plates go on the bottom (stability), while wine glasses go on the top (safety).
- Execution: It draws specific vectors (blue/red arrows) showing the exact trajectory for a robotic arm (or human hand) to take.
✅ The Factory Application (Bin Picking & QC)
The Scenario:
A bin of mixed automotive connectors arrives at a quality control station.
The Agentic Process:
- Identification: The model identifies a specific 12-pin connector needed for the current chassis.
- Defect Detection: It “zooms” in on the pins using code execution to measure if they are bent—something standard models might miss in a wide shot.
- Sorting: It generates coordinates for a robotic arm to pick the part and place it in the assembly tray, orienting it correctly.
- Result: The system handles a mixed bin without needing a vibratory bowl feeder or pre-sorting, reducing hardware costs.
Why This Matters for Automation
Dynamic Adaptability
Traditional robots are rigid. If you move the tray two inches to the left, the robot fails. Agentic Vision allows the robot to “see” the move and adjust its path in real-time, much like a human would. This flexibility allows factories to switch product lines in hours rather than weeks.
Verifiable Accuracy
In regulated industries like pharmaceuticals or aerospace, “hallucination” is not an option. Because Agentic Vision uses code to measure and verify what it sees, it provides a deterministic audit trail. It doesn’t just say “the vial is full”; it can log the pixel height of the liquid level.
Conclusion
Gemini 3 Flash’s Agentic Vision represents a shift from AI that describes the world to AI that navigates it. By combining visual perception with the logical rigor of code execution, Google has created a tool that bridges the gap between digital reasoning and physical action.
For industries ranging from logistics to home robotics, the ability to “understand” a scene—knowing that a glass is fragile and belongs on a high shelf, or that a circuit board is misaligned—is the first step toward true autonomy. The kitchen cabinet was just the training ground; the real work begins on the factory floor.
Frequently Asked Questions About Agentic Vision in Gemini 3 Flash
What is the "Think, Act, Observe" loop in Agentic Vision?
It is a process where the AI analyzes an image (Think), writes code to inspect specific details or measure pixels (Act), and reviews the code’s output to confirm its findings (Observe), ensuring higher accuracy than a simple visual scan.
Can Gemini 3 Flash control robots directly?
Yes, when paired with a robotics API. The model can output coordinate data (JSON/Python) that robotic arms interpret as movement commands, allowing for “zero-shot” control where the robot performs tasks it wasn’t explicitly trained for.
How does this differ from traditional machine vision?
Traditional machine vision relies on matching images against a pre-trained database of specific objects. Agentic Vision uses reasoning to understand novel objects and their spatial relationships, allowing it to handle unstructured environments.
Is Agentic Vision available for enterprise use?
Yes, Agentic Vision is available via Google AI Studio and Vertex AI for developers and enterprises, allowing businesses to integrate these capabilities into their internal tools and automation workflows.
Does Agentic Vision work with video?
Yes, Gemini 3 Flash processes video input, allowing it to track objects over time, understand motion trajectories, and predict where moving items (like packages on a conveyor belt) will end up.
Why is code execution important for vision?
Code execution grounds the AI’s “vision” in math. Instead of guessing the number of items or their size, the AI writes a script to count or measure them, drastically reducing “hallucinations” or visual errors.

{kind=link}